Xpath
XPath is used to navigate through elements and attributes in an XML document. XPath is designed to allow the navigation of XML documents, with the purpose of selecting individual elements, attributes, or some other part of an XML document for specific processing.
What is XML?
The Extensible Markup Language (XML) is the context in which the XML Path Language, XPath, exists. XML provides a standard syntax for the markup of data and documents. XML documents contain one or more elements. If an element contains content,whether other elements or text, then it must have a start tag and an end tag. The text contained between the start tag and the end tag is the element’s content.
Absolute XPath
Absolute XPath starts with the root node or a forward slash (/).
Example:
If the Path we defined as
1. html/head/body/table/tbody/tr/th
If there is a tag that has added between body and table as below
2. html/head/body/form/table/tbody/tr/th
The first path will not work as ‘form’ tag added in between
Relative Xpath
A relative xpath is one where the path starts from the node of your choise – it doesn’t need to start from the root node.
It starts with Double forward slash(//)
Syntax:
//table/tbody/tr/th
Selecting Elements:
XPath uses path expressions to select nodes in an Web document. The node is selected by following a path or steps. The most useful path expressions are listed below:
| Sr. No. | Expression | Description |
| 1 | nodename | Selects all nodes with the name “nodename” Example div, a, input, button etc. |
| 2 | Unknown Elements | XPath wildcard character * can be used to select unknown Web elements. |
| 3 | / | Selects child from the current node |
| 4 | // | Selects Descendants from the current element that match the selection no matter where they are |
| 5 | . | Selects the current node |
| 6 | .. | Selects the parent of the current node |
| 7 | @ | Selects attributes |
Predicates
Predicates are used to find a specific node or a node that contains a specific value [and/or based on some condition]. Predicates are always written inside square brackets.
| Sr. No. | Path Expression | Result |
| 1 | //div[1] | Selects the first div element from the root |
| 2 | //div[@id=’mainMenu’] | Selects all the div having id as mainMenu |
| 3 | last() | Matches the Last position from the list |
| //li[last()] | Selects the last li from list of li | |
| 4 | text() | Get the text node of element |
| //a[text()=’Home’] | Selects all the a(anchor) having text Home | |
| 5 | position() | Matches the particular position from the list |
| //li[position()<3] | Selects the first two li from list of li | |
| 6 | contains(string1,string2) | Matches if the string2 contains in string1 |
| 7 | starts-with(string1,string2) | Matches if the String1 starts with String2 |
| 8 | ends-with(string1,string2) | Matches if the String1 ends with String2 |
| 9 | matches(string,pattern) | Matches if the String1 match with given regular expression pattern |
| 10 | upper-case(string) | Convert the string to Uppercase |
| 11 | lower-case(string) | Convert the String to Lowercase |
Selecting a specific row of a table.
You may come across a situation where you might need to click (please refer below screen shot) on either edit or delete button of a row in a table. It might depend upon specific id or some name.
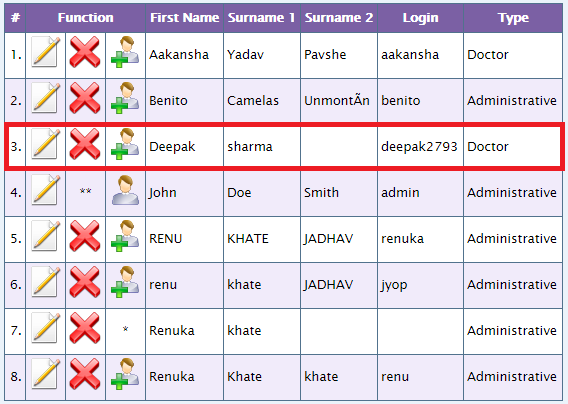
Step 1: first select the table say you have this table , like //table (if it is the only table, if there are other table then use predicates for selecting this table e.g. //table[@class=’classname’])
Step 2: then use //tr to select all the tr in this table. You must use // because there could be a node th or tbody,in order to skip those use // and not /
Step 3: Now say I want to select a row whose login name is deepak2793. Looking at step 1 & to we have come up to xpath //table//tr. It will select all the row of the table now to select the specific row use //table//tr[td[text()=’deepak2793′]] it will select the row whose login name is deepak2793.
Step 4: now to select an icon of edit/delete simply append td[2] to //table//tr[td[text()=’deepak2793′]] for edit and td[3] to //table//tr[td[text()=’deepak2793′]] for delete
So final xpath becomes
//table//tr[td[text()=’deepak2793′]]//td[2] for edit
//table//tr[td[text()=’deepak2793′]]//td[2] for delete